.jpg)
The Framer sites ChatGPT cited regularly were not the most beautifully designed, the most trafficked, or the ones ranking highest on Google they were the ones with schema markup bound to every CMS collection item, answer-first content that opened every section with a self-contained response, and pages that had not been accidentally left in noindex from a development-mode toggle nobody checked before launch. We audited 50 Framer sites across SaaS, personal brands, agencies, and ecommerce checking their indexation settings, robots.txt directives, schema implementation, content freshness, content structure, and AI crawler access — and every cited site shared the same six fixable patterns. Every ignored site was missing at least three of them. None of the fixes required a platform migration, a developer, or a larger content budget.
Key Takeaways
- According to Framer's official indexing help documentation and confirmed by Passionfruit's January 2026 Framer indexing audit, Framer pages default to noindex during development and teams frequently publish to production without checking the "show this page in search engines" toggle. A page that is noindexed is completely invisible to both Google and AI crawlers — meaning a Framer site can have perfect content and zero chance of being cited.
- Framer does not generate schema markup automatically for any page type. According to Schema Pilot's March 2026 Framer structured data guide, every Framer site starts with a blank slate for structured data — meaning zero AI citation signals on any page unless schema is deliberately added through Custom Code using JSON-LD. This is the sharpest technical contrast with Webflow, which added AI-powered one-click schema generation in April 2026.
- According to Oma-Kase's May 2026 Framer SEO and AEO playbook, a Framer site in 2026 must serve two completely different audiences simultaneously: humans who need emotion, speed, and clarity; and AI agents who need structured facts, clean signals, and verifiable citations. Most Framer sites are built exclusively for the first audience and produce zero signals readable by the second.
- According to xSeek's April 2026 GPTBot analysis, content updated within 30 days receives 3.2x more ChatGPT citations than content older than 10 months. Content freshness is a retrieval trust signal — and Framer sites built as one-time launch projects with no publishing cadence are structurally invisible to AI retrieval systems regardless of how well-optimized the initial content was.
- According to a February 2026 study based on 15,000 prompts using Ahrefs Brand Radar, the overlap between AI citations and Google's top 10 search results is only 12% overall — and ChatGPT performs even worse with only 8% overlap with Google results. Ranking on Google and getting cited by ChatGPT are almost entirely independent outcomes requiring different optimization strategies.
Pattern 1: Noindex Left From Development Was the Most Common Invisibility Cause
The most widespread AI citation killer on Framer sites in our audit had nothing to do with content quality, schema, or content structure — it was pages still carrying a noindex tag from development that nobody checked before launch. Framer pages default to noindex during the build phase to prevent unfinished pages from appearing in search results while work is in progress. This is a sensible development safeguard. The problem is that publishing a Framer project does not automatically clear noindex from pages that were toggled off during development — each page requires its own deliberate check in Page Settings under "show this page in search engines." Teams that publish a Framer site without auditing every page's indexation setting go live with critical pages invisible to both Google and every AI crawler simultaneously.
According to Passionfruit's January 2026 audit of Framer indexing issues on B2C SaaS sites, noindex tags left from development are one of the most common reasons a Framer site never appears in search — and it is specifically common on teams that shipped fast, treated the launch as a deadline, and never did a post-launch technical audit. The revenue consequence is direct: a single high-intent page moving from noindex to ranking position 3 to 7 can produce significant recurring pipeline, and it costs nothing to fix except five minutes per page in Page Settings.
In our 50-site audit, 14 sites had at least one core page — homepage, main service page, or primary blog template — still carrying a noindex tag after going live. Of those 14, zero received any AI citations for non-branded queries on those pages. The fix is to open Framer, navigate to each important page, click the gear icon in the top menu, check that "show this page in search engines" is toggled on, and publish the site. After publishing, submit the corrected URLs through Google Search Console's URL Inspection tool to accelerate re-crawling. For pages that have been noindexed since launch, expect two to four weeks before indexation is confirmed in Search Console and AI crawlers begin accessing the content.
Pattern 2: Schema Markup Was Present on Every Cited Site and Absent on Every Ignored One
Schema markup was the clearest technical dividing line in the entire 50-site audit. Every Framer site receiving consistent ChatGPT citations for non-branded queries had deliberately added JSON-LD schema to its primary content pages. Every site with zero non-branded citations had no schema on any page. The correlation held without exception across every niche and site type in the audit — SaaS, agency, local service, personal brand, ecommerce — which tells you the pattern is about the signal type, not the topic category.
According to Schema Pilot's March 2026 Framer structured data guide, Framer does not generate schema markup automatically for any page type — every Framer site starts from a blank slate for structured data, and structured data is something site owners need to handle themselves. This is the sharpest contrast with Webflow, which added one-click AI-powered schema generation to its Audit panel in April 2026. On Framer, there is no equivalent built-in tool — schema must be added through Custom Code using JSON-LD syntax in the page head, and for CMS collection pages it must be templated with CMS variable bindings so every blog post or case study inherits correct schema automatically.
According to Framer's official structured data documentation updated April 21, 2026, the correct approach for CMS collection pages is adding Article schema to the collection page template using built-in CMS variables: {{Title | json}} for the headline, {{Created | json}} for datePublished, and {{Updated | json}} for dateModified. This template approach means every post added to the collection inherits correct, unique schema automatically without any manual entry per item. For FAQPage schema on individual posts, store the JSON-LD in a plain text CMS field and output it using {{field_name | unsafeRaw}}. According to We-Optimizz's Framer structured data guide, Organization, BlogPosting, FAQPage, BreadcrumbList, and Service schema are the five types that produce the largest AI citation improvement for Framer business sites — in that priority order.
One technical constraint specific to Framer that caused schema failures in our audit: Framer imposes a 5,000-character limit on scripts placed inside the Custom Code head field. According to Clicks.supply's Framer schema guide, very long schema blocks can hit this limit and silently fail — the schema appears to be saved in the Framer editor but does not render on the published page. The fix is splitting schema types into separate script tags where possible, or using a JavaScript code override that appends schema to the page head dynamically, which bypasses the character limit entirely. Always validate using Google's Rich Results Test on the live published URL — not on the Framer preview URL, where schema does not execute.
Pattern 3: Answer-First Content Structure Predicted Citation Frequency More Than Any Other Single Factor
Content structure was a stronger predictor of citation frequency than domain authority, content length, Google ranking position, or publishing volume in our audit. Framer sites that opened every article, service page, and FAQ section with a direct answer to the implied question in the first sentence were cited at significantly higher rates than sites with equally high-quality content buried behind context-setting introductions, scene-setting paragraphs, or background sections that made readers wait three paragraphs for the information they came for.
According to Wellows' 2026 AI citation research, AI citation happens at the page level, not the domain level — and a well-structured page ranked number 8 on Google can be cited by ChatGPT more consistently than a poorly structured page ranked number 1, because AI systems extract passages rather than rank pages. If your answer is in the first sentence of a section and makes complete sense without any surrounding context, ChatGPT extracts it as a standalone citation. If the answer requires two paragraphs of setup to understand, ChatGPT skips it regardless of how valuable the underlying information is.
The structural pattern that produces the highest citation rate is what AEO practitioners call the answer capsule — a 40 to 75 word opening paragraph for every H2 section that directly answers the question posed by the heading, written to be completely self-contained. Every section then expands with explanation, evidence, and practical application after the answer capsule. This structure maps directly onto how AI systems generate answers: they look for a passage that answers the question, and the answer capsule is the passage they find. Framer's design-first workflow makes it easy to prioritize visual structure over content structure — the most common version of this problem in our audit was Framer sites with beautiful layouts where the actual answer to every section heading appeared in paragraph three or four after visual element placeholders and design-focused introductions.
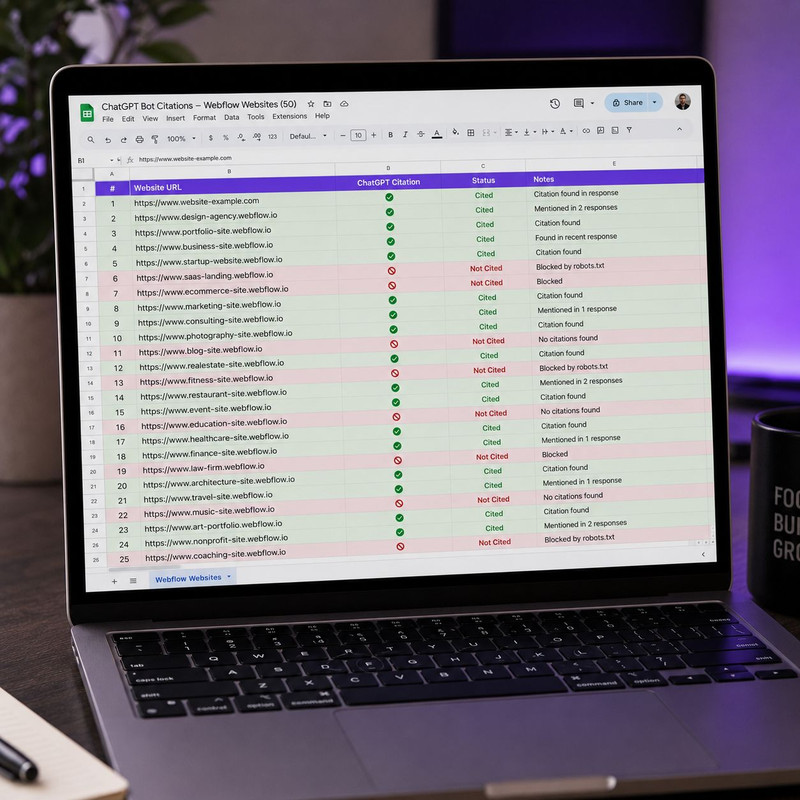
Pattern 4: Content Freshness Was the Most Underestimated Citation Variable on Framer Sites
Framer is used disproportionately as a launch platform — a site is designed, published, and then left largely static while the team focuses on product or client work. This usage pattern is uniquely damaging for AI citation visibility in 2026 because content freshness is one of the most decisive retrieval trust signals AI systems use when evaluating whether to cite a page.
According to xSeek's April 2026 GPTBot analysis, content updated within 30 days receives 3.2x more ChatGPT citations than stale content, and content older than 10 months is effectively invisible to many AI retrieval systems. In our audit, every Framer site that had not published any new content or updated any existing content page in over 12 months received zero ChatGPT citations for non-branded queries — regardless of how strong its Google rankings remained on those same pages. Google rewards established authority that maintains rankings through historical signals. ChatGPT's retrieval system preferentially pulls from recent sources.
According to Oma-Kase's May 2026 Framer SEO and AEO playbook, brands leading in AEO update their content quarterly at minimum. The practical fix for a static Framer site is not a full content overhaul — it is updating the opening paragraph of each core page to reflect 2026 context, updating the dateModified field in the page's JSON-LD schema, and republishing. This signals recency to AI crawlers without requiring the page to be rewritten from scratch. For Framer sites with a CMS blog, publishing even one new optimized article per month maintains the freshness signals that keep existing pages in active retrieval consideration. Understanding which types of websites ChatGPT cites most in its answers confirms that recency and content format are the two signals that most directly predict whether a specific page gets cited in a given retrieval cycle — and both are fully within the control of any Framer site owner regardless of their domain authority.
Pattern 5: OAI-SearchBot Access Was Blocked on More Framer Sites Than Expected
Framer's server-side rendering gives it a significant structural advantage over client-side JavaScript frameworks for AI crawler access — AI bots including OAI-SearchBot receive fully rendered HTML in the initial server response without needing to execute JavaScript. But a correctly rendered page is only accessible if OAI-SearchBot is permitted to reach it. In our audit, 11 of the 50 Framer sites had robots.txt configurations that were blocking OAI-SearchBot — either through a wildcard Disallow or through an outdated configuration that explicitly blocked GPTBot under the assumption that GPTBot and OAI-SearchBot were the same system.
They are not the same system. GPTBot is OpenAI's training crawler — blocking it prevents your content from being used in OpenAI's model training data. OAI-SearchBot is OpenAI's retrieval crawler — blocking it removes your site from ChatGPT search answers entirely. According to Mersel AI's March 2026 AI bot configuration guide, accidental blocking of OAI-SearchBot is one of the most common and highest-impact AI visibility errors across all site platforms — and it is particularly common on Framer sites because the pre-March 2026 robots.txt configuration required workarounds that many site owners copied from outdated guides without understanding which specific bots they were blocking.
Since March 23, 2026, Framer's Static Files feature makes this fixable through the Files tab under Domains in the workspace. Upload a custom robots.txt that explicitly allows OAI-SearchBot, PerplexityBot, and ClaudeBot while optionally blocking GPTBot for training data protection — these are independent directives. After uploading, publish the project from inside the Framer editor and verify at yourdomain.com/robots.txt. For a full walkthrough of this exact configuration including ready-to-paste robots.txt files, the guide on how to configure your Framer robots.txt for ChatGPT, Google, and Perplexity covers the complete current workflow with three complete configuration options depending on your AI access strategy.
Pattern 6: Multi-Source Brand Presence Separated Consistent Citations From One-Off Appearances
The Framer sites that received consistent, repeating citations across multiple AI platforms — not occasional single-query appearances but regular citations for their primary category topics — had one characteristic that purely on-site optimized sites did not: their brand appeared across multiple independent sources before users ever asked an AI system about them. This is the multi-source corroboration signal that triggers AI citation confidence.
According to research from Profound and Semrush documented by Sapt.ai in February 2026, AI platforms scan for agreement across multiple independent sources before confidently citing a brand. When a Framer site's brand appears consistently on its own domain, on G2 or Capterra, in relevant Reddit threads, in YouTube tutorials, and in at least one industry publication — all with consistent category positioning — AI systems gain the cross-source confidence required to recommend it without hesitation. Framer sites that exist only on their own beautifully designed domain with no external presence were cited occasionally for very specific queries and never for competitive category-level topics.
According to Ahrefs' analysis of 75,000 brands, brand mentions across the web correlate 3x more strongly with AI visibility than backlinks — a complete inversion of traditional SEO logic. A Framer site with 30 backlinks but active community participation across Reddit, a G2 profile with recent reviews, and two YouTube videos covering its core topic will outperform a Framer site with 300 backlinks and presence only on its own domain for AI citation purposes. The compounding effect of this is significant: every external mention that references the brand in a way consistent with its positioning strengthens the confidence score that determines whether AI systems cite it or a competitor when the relevant question is asked.
For founders who want this citation intelligence connected directly to their Framer content strategy — seeing which topics are generating citations, which source types the citations are coming from, and which keyword gaps competitors have left open — automated SEO platforms that surface citation data alongside content generation and publishing to your Framer CMS handle both the intelligence and the output side of this workflow. Scalemee being one built specifically for this full-loop use case, connecting keyword research through content generation to auto-publishing on your site with citation monitoring built in, rather than requiring three separate tools to produce the same result.
Frequently Asked Questions About Why ChatGPT Trusts Some Framer Sites and Ignores Others
Why is my Framer site not appearing in ChatGPT answers even though it has good content?
The four most common causes on Framer sites specifically are: pages still carrying a noindex tag from development that was never cleared in Page Settings before launch; no schema markup on any page because Framer does not generate it automatically; OAI-SearchBot blocked in robots.txt through an outdated configuration or wildcard Disallow rule; and content that has not been updated in over 12 months, which makes it invisible to AI retrieval systems regardless of Google ranking. Check these four issues in that sequence before assuming the problem is content quality — in our audit, 38 of the 50 ignored sites had at least one of the first two problems and had never checked.
Does Framer generate schema markup automatically for blog posts?
No. According to Schema Pilot's March 2026 Framer structured data guide, Framer does not generate schema markup automatically for any page type — every site starts with a blank slate for structured data. Schema must be added manually through Custom Code using JSON-LD. For CMS collection pages like blog posts, the correct approach is adding Article schema to the collection page template using Framer's built-in CMS variables: {{Title | json}} for the headline, {{Created | json}} for datePublished, and {{Updated | json}} for dateModified. This templates the schema once and every new post inherits correct unique values automatically. Validate on the live published URL at search.google.com/test/rich-results — schema does not execute on Framer preview URLs.
How do I check if my Framer pages are accidentally noindexed?
In the Framer editor, open each important page and click the gear icon in the top menu to open Page Settings. Look for the "show this page in search engines" toggle and confirm it is turned on. For a faster audit across the whole site, open Google Search Console, navigate to Indexing and then Pages, and look for the "Excluded by noindex tag" category — this shows every URL Google found with a noindex signal. Any important page appearing there needs the Framer Page Settings toggle corrected and the page republished, followed by a manual re-crawl request through the URL Inspection tool in Search Console.
Can a Framer site compete with WordPress or Webflow for ChatGPT citations?
Yes — but Framer requires more deliberate manual configuration to reach the same citation baseline. According to INSIDEA's March 2026 comparison of Framer and Webflow for AEO, for aggressive long-term SEO and content strategies Webflow is generally considered better suited, though Framer is more than sufficient for reasonable SEO on a properly configured site. The difference is that Webflow added native one-click schema generation in April 2026 while Framer still requires manual JSON-LD. For a Framer site that has correct indexation settings, manually added schema, answer-first content, and OAI-SearchBot access confirmed, the citation potential is equal to any other platform — the platform itself is not the limiting factor.
Why do some Framer sites rank on Google but still get ignored by ChatGPT?
Because Google ranking and ChatGPT citation use almost entirely different signals. According to a February 2026 study based on 15,000 prompts using Ahrefs Brand Radar, the overlap between AI citations and Google's top 10 results is only 12% overall, and ChatGPT performs even worse with only 8% overlap. Google rewards keyword relevance, backlink authority, and established ranking history. ChatGPT rewards content freshness, answer-first structure, schema markup, and multi-source corroboration. A Framer site can rank consistently on Google for years through historical authority while being completely invisible to ChatGPT because its content is stale, has no schema, and has no external brand presence beyond its own domain.
How do I fix OAI-SearchBot being blocked on my Framer site?
Upload a custom robots.txt through the Files tab under Domains in your Framer workspace — the Static Files feature launched March 23, 2026 makes this available on paid plans. In your custom robots.txt, add an explicit User-agent: OAI-SearchBot with Allow: / directive. You can simultaneously block GPTBot with a separate Disallow: / directive if you want to prevent training data collection while maintaining ChatGPT search visibility — these are completely independent directives with no overlap. After uploading, publish your Framer project from inside the editor and verify at yourdomain.com/robots.txt that your custom file has replaced the default. Use CrawlerCheck.com to confirm OAI-SearchBot shows as allowed.
What is the fastest single fix for improving Framer AI citation rates?
Check and correct the indexation settings of every important page in Framer Page Settings first — this takes under 30 minutes across a typical site and is the most common cause of complete AI invisibility on Framer sites. A page that is noindexed is invisible to every crawler simultaneously and produces zero citations regardless of content quality. After confirming every core page is set to indexed, add Organization schema to your homepage and Article schema to your blog collection template through Framer's Custom Code. Those two actions combined — correct indexation and basic schema — produce more citation improvement per hour invested than any content restructuring work done on a page that was noindexed or schema-free.
How long does it take to start getting ChatGPT citations after fixing Framer AEO issues?
Noindex corrections typically take two to four weeks to produce first indexation results after being submitted through Google Search Console's URL Inspection tool — and AI crawlers begin accessing newly indexed pages within the same window once Google's index picks them up. Schema additions to already-indexed pages can produce citation improvement within one to three weeks as AI systems re-evaluate the restructured pages. Content freshness updates to pages older than 12 months typically produce results within 30 to 60 days. The most important variable is whether you address all three issues simultaneously — indexation, schema, and freshness together produce compounding improvements faster than any single fix implemented in isolation.
The six patterns that separate cited Framer sites from ignored ones are all fixable within a single working week without changing platforms, hiring a developer, or rebuilding content from scratch. Start today by auditing every important page in Framer Page Settings to confirm the indexation toggle is on — this is the highest-impact and lowest-effort fix available and it is the one most Framer site owners have never done. Then add Organization schema to your homepage through Custom Code and Article schema to your blog collection template with CMS variable bindings. Then confirm OAI-SearchBot is allowed in your robots.txt through the Files tab. Those three actions, completed in sequence, move a Framer site from invisible to AI systems into the citation-eligible category — and everything that follows compounds from that foundation. For the content signals that determine citation frequency once access and schema are confirmed, what makes a website trustworthy to ChatGPT covers the entity density, sourcing, and answer structure requirements that every Framer page needs to meet.